
在做微信小程序用户数据入mysql存储时遇到了问题,只要含有emoji表情会导致本条字段无法入库。
经过查询得出两条方案:
1.更改数据库编码
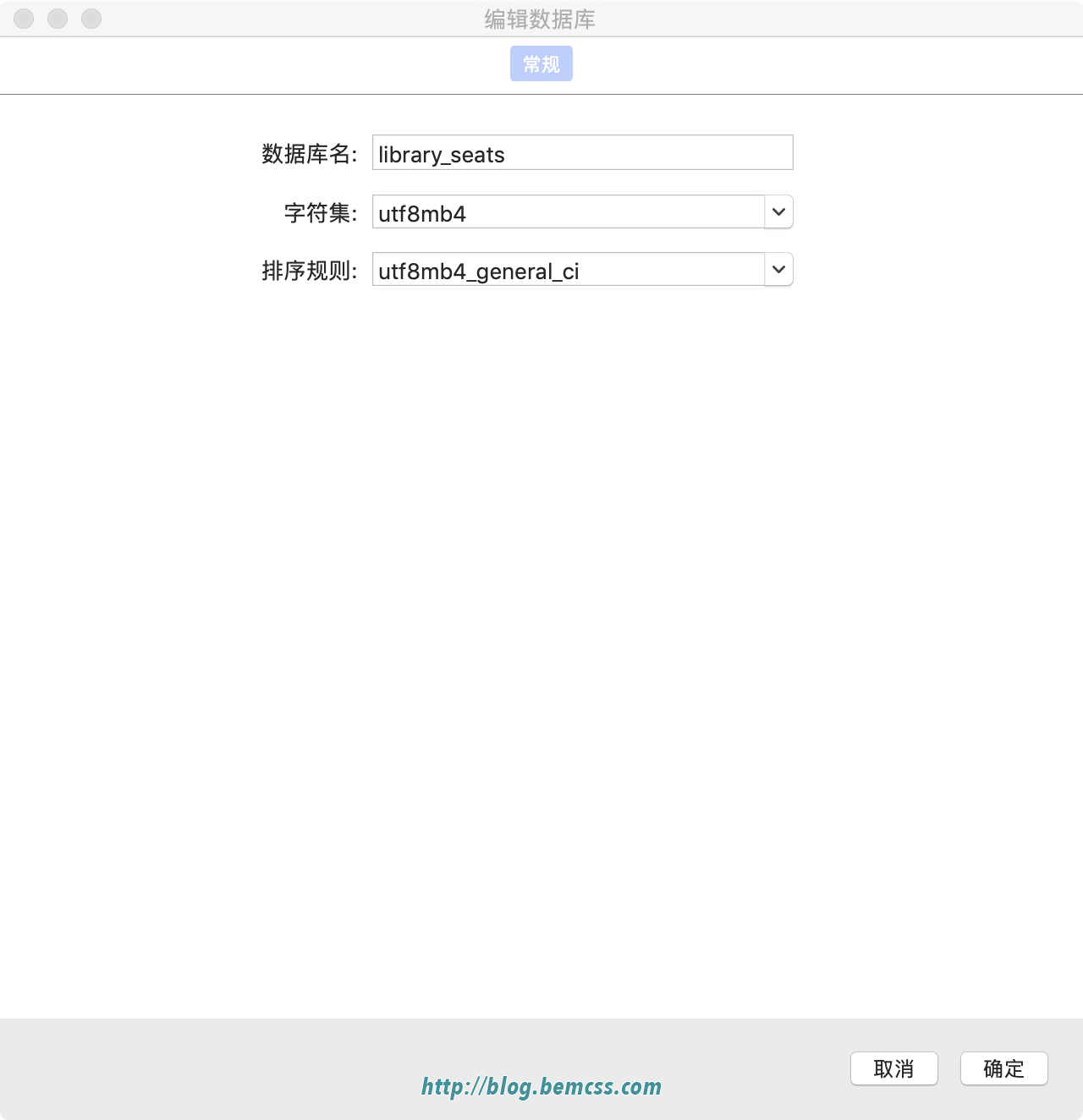
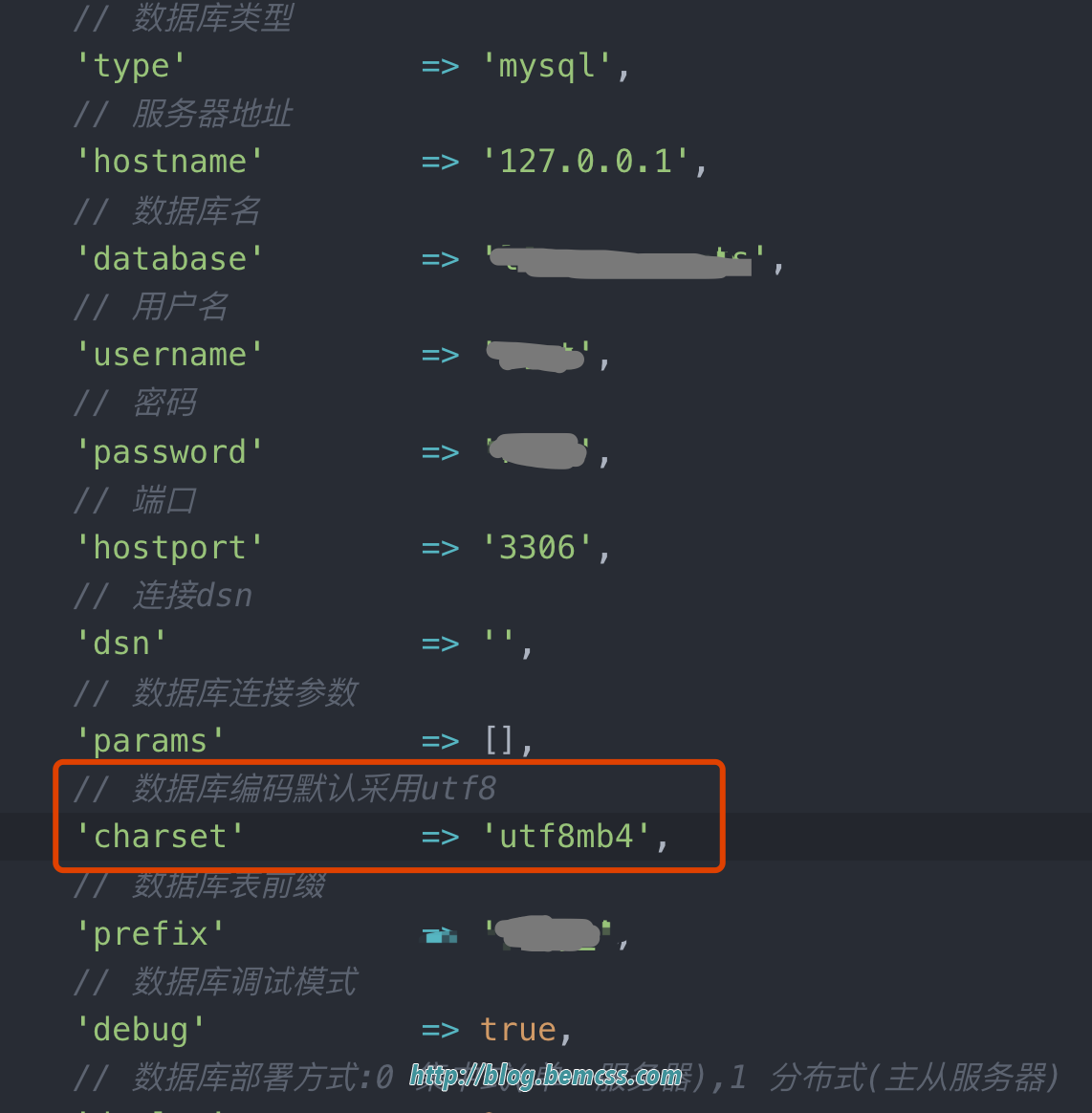
修改MySQL数据库字符集, 把数据库字符集从utf8 修改为支持1-4 个字节字符的utf8mb4。
从MySQL 5.5.3版本开始,数据库可支持4个字节的utf8mb4 字符集,一个字符最多可以有4个字节,所以能支持更多的字符集,故能存储Emoji表情符号。从 mysql 5.5.3 之后版本基本可以无缝升级到 utf8mb4 字符集。同时,utf8mb4兼容utf8字符集,utf8 字符的编码、位置、存储在utf8mb4与utf8字符集里一样的,不会对有现有数据带来损坏。
修改数据库字符集character-set-server=utf8mb4 重启数据库生效。
修改database 的字符集为 utf8mb4 alter database dbname character set utf8mb4
修改表的字符集 为utf8mb4 , alter table character set = utf8mb4
2.将emoji表情转译为特殊编码,在输出时再将特殊编码转译回emoji表情
/**
把用户输入的文本转义(主要针对特殊符号和emoji表情)
*/
function userTextEncode($str){
if(!is_string($str))return $str;
if(!$str || $str=='undefined')return '';
$text = json_encode($str); //暴露出unicode
$text = preg_replace_callback("/(\\\u[ed][0-9a-f]{3})/i",function($str){
return addslashes($str[0]);
},$text); //将emoji的unicode留下,其他不动,这里的正则比原答案增加了d,因为我发现我很多emoji实际上是\ud开头的,反而暂时没发现有\ue开头。
return json_decode($text);
}
/**
解码上面的转义
*/
function userTextDecode($str){
$text = json_encode($str); //暴露出unicode
$text = preg_replace_callback('/\\\\\\\\/i',function($str){
return '\\';
},$text); //将两条斜杠变成一条,其他不动
return json_decode($text);
}优点
1、只转换表情,不会转换中文,所以数据还是直接可读的
2、不会把表情转换为其它标准,只有一个简单的,固定的转换算法,也就是说不需要一个表情库来对照着转换,所以以后其它人要使用这个数据的时候,也很容易知道每个表情是对应的哪个。就算苹果大爷又增加了表情,也不需要做什么额外的修改。
3、可以无限decode输出的都是正确的内容。因为有的时候可能需要在一次请求中的两个地方做decode,其它decode多次会把正确的数据改成其它数据,这个不会。
缺点
1、看了上面的代码就知道,这个是强制修改字符编码中,指定区间内的编码,也就说有可能误杀,也有可能有超出这个区间的emoji没杀到。不过仅仅是在字符前加反斜杠,即使误杀了,发现之后也很容易改回来。
2、插入数据与接口返回数据前需要做转码工作,性能有所损耗。
